CrowdStrike® Falcon LogScale™The world’s leading AI-native platform for SIEM and log management
Rapidly shut down threats with real-time detections, blazing-fast search, and cost-effective data retention.
See Falcon LogScale in action
We've always said, "You don’t have a malware problem, you have an adversary problem." Discover how to detect, investigate and hunt for advanced adversaries with Falcon LogScale by watching a fast-paced demo. You'll see firsthand how Falcon LogScale accelerates security operations with petabyte-scale log management and delivers real-time detections and lightning-fast search to stop threats.

“Switching to Falcon LogScale saves us $2-3 million every three years in infrastructure costs and $1-2 million a year in licensing costs … At any given point, we have around 2,500 searches happening, and most complete in seconds.”
- Stian Bratlie, Systems Engineer, SpareBank 1
Legacy SIEM solutions can’t keep pace with data growth
Slow search speed
You can’t stay ahead of threats if your SIEM takes minutes or hours to return query results.
Blind spots
You can’t protect what you can’t see, and legacy SIEMs are too complex and too costly to store everything.
Exorbitant costs
You shouldn’t have to compromise on how much data you ingest and how long you retain it to stay on budget.
Why choose Falcon LogScale?
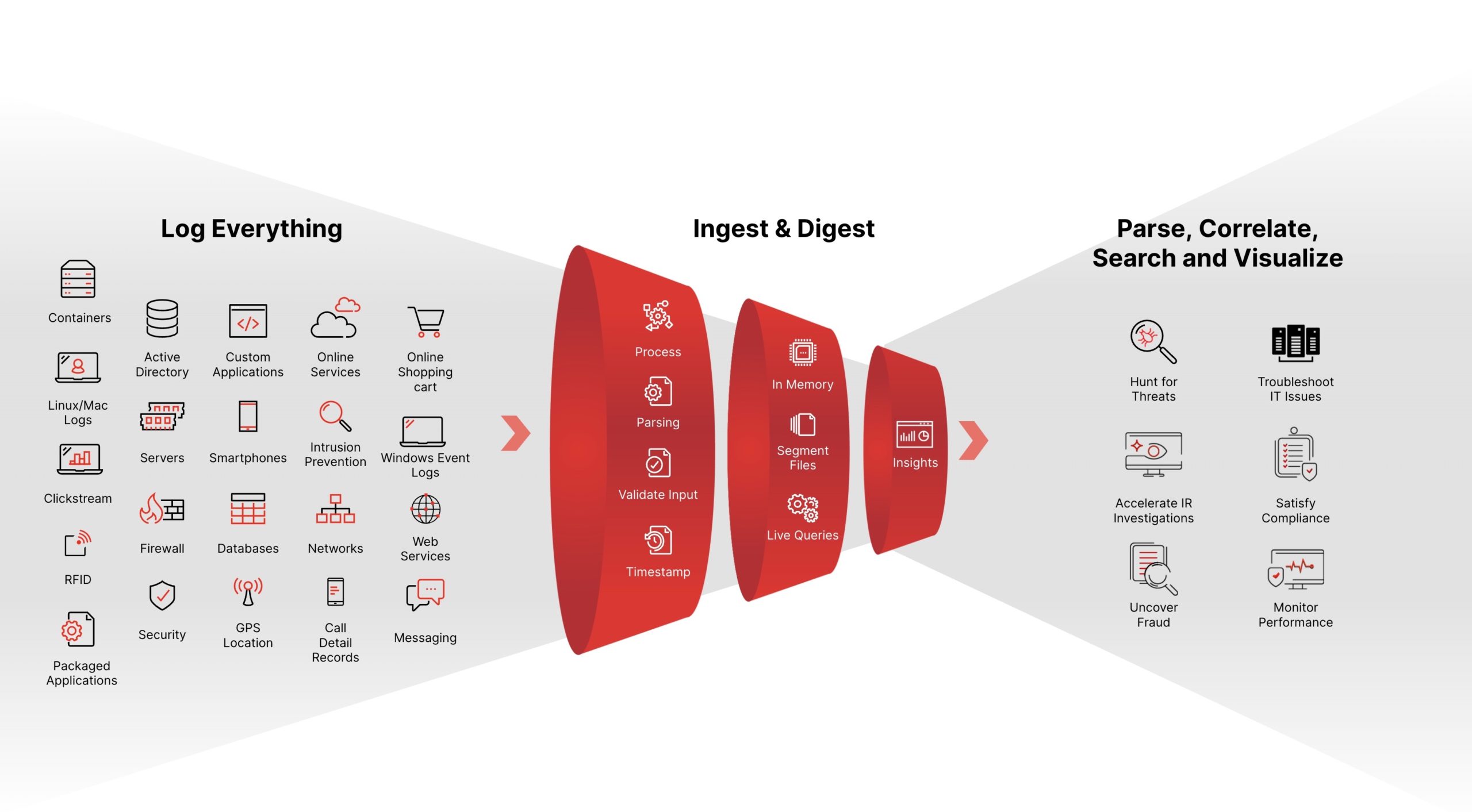
Built for the speed and scalability requirements of the modern SOC, Falcon LogScale lets you stop breaches with real-time alerting, blazing-fast search, and world-class threat intelligence. You can log everything to answer anything, while reducing complexity and cost.
Security logging at petabyte scale
A powerful, index-free architecture lets you log all your data and retain it for years while avoiding ingestion bottlenecks.
- Collect more data for threat hunting and investigations.
- Scale to over 1 PB of data ingestion per day with negligible data loss or performance impact.
- Choose between cloud-native or self-hosted deployment.
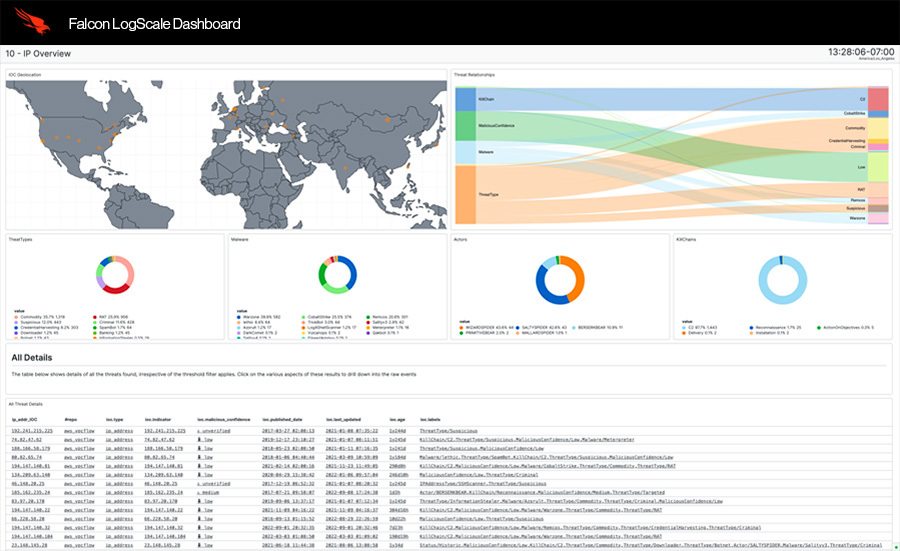
Real-time search to outpace adversaries
Aggregate, alert on, and visualize live data as it streams into Falcon LogScale. Monitor the health of your systems, detect threats immediately, and identify issues early.
- Get real-time alerting, search, and visualization.
- Achieve sub-second latency, even with complex queries.
- View graphical dashboards with live data.
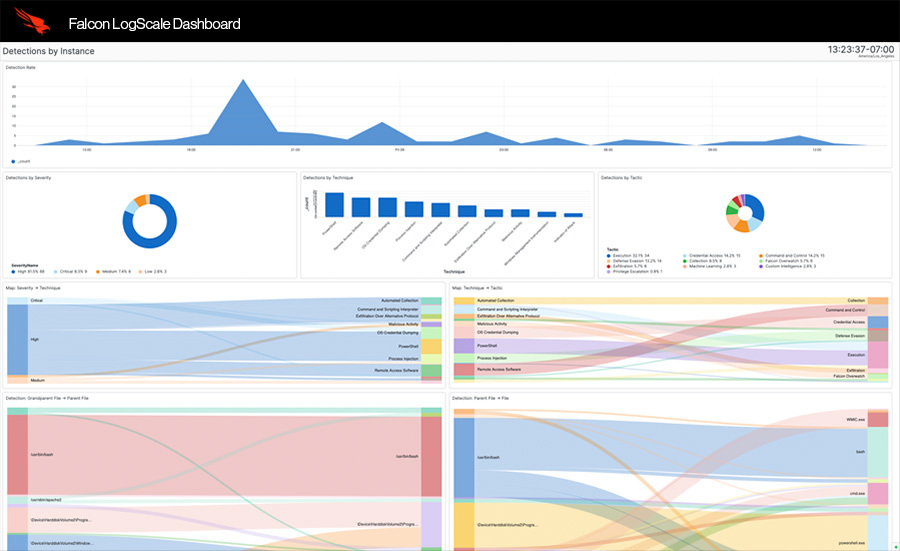
360° visibility to eliminate blind spots
Consolidate all of your data to break down silos and meet your security and observability requirements with one solution.
- Let security, IT, and DevOps teams hunt for threats, monitor performance, and achieve compliance.
- Search across 3 billion events in less than 1 second.
- Easily query any field with free text search.
Falcon LogScale by the numbers
Uncover security and reliability issues before they impact your business.
Sub-second latency
Detect threats faster by processing incoming data in under a second.*
Up to 150x faster
Find suspicious activity in a fraction of the time of traditional security logging tools.2
Up to $9M savings
Estimated reduction in total cost of ownership over three years for a Norwegian bank by switching to Falcon LogScale.
Calculate your log management savings
Estimate savings
Calculate your log management savings
Estimate savings
Falcon LogScale key capabilities






Customer case studies



See Falcon Next-Gen SIEM live
See Falcon Next-Gen SIEM live
-
When you find a threat, you need to investigate and stop it - fast. Watch this one-minute video to find out how Falcon LogScale’s high-speed search lets you detect and respond to incidents faster than you ever thought possible.
Video Length: 1:13
-
Monitoring security events in real-time empowers you to find stealthy threats and spot attack trends early. See how Falcon LogScale’s live dashboards provide a flexible, intuitive way to visualize your security data.
Video Length: 1:24
-
When adversaries infiltrate your organization, you need rich investigative details and intelligence to find and root them out quickly. Watch to learn how Falcon LogScale’s data enrichment feature accelerates threat hunting, so you can stop adversaries with complete context.
Video Length: 1:13
* Outcomes based on real Business Value Assessments for individual customers
2 Performance measured against two leading security logging platforms evaluating the speed to query DNS requests to top abused domains.